
前言
此篇记录一下本人对链表的理解,重点讲解链表的插入与删除算法,相信大家在学习数据结构的时候,第一篇就是链表。简直是给了我一个下马威。我对应它放弃了多次,早在1年前我就接触了链表,emmm,放弃。始终不甘心,然后等到高考暑假后再次鼓起勇气认识它,好吧,又被它打跑了。终于在前几天重新再来学习链表,功夫不负有心人,彻彻底底的搞懂了链表。
基本概念
链表由n个结点链组成,第一个结点的存储位置叫做头指针,最后一个结点的指针为“空”(NULL)
结点:包括数据域和指针域
头指针:指向链表中第一个结点的地址
头结点:在单链表的第一个结点前附设的一个结点
头指针是链表的必要元素,头结点是为了操作的统一和方便而设定的,其数据域一般无意义(可用来保存链表的长度),头结点可有可无。
单链表
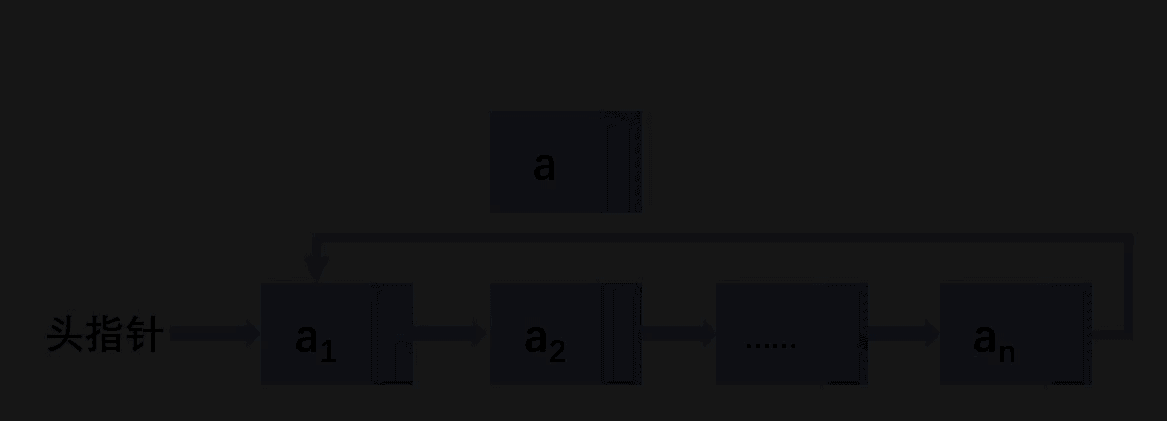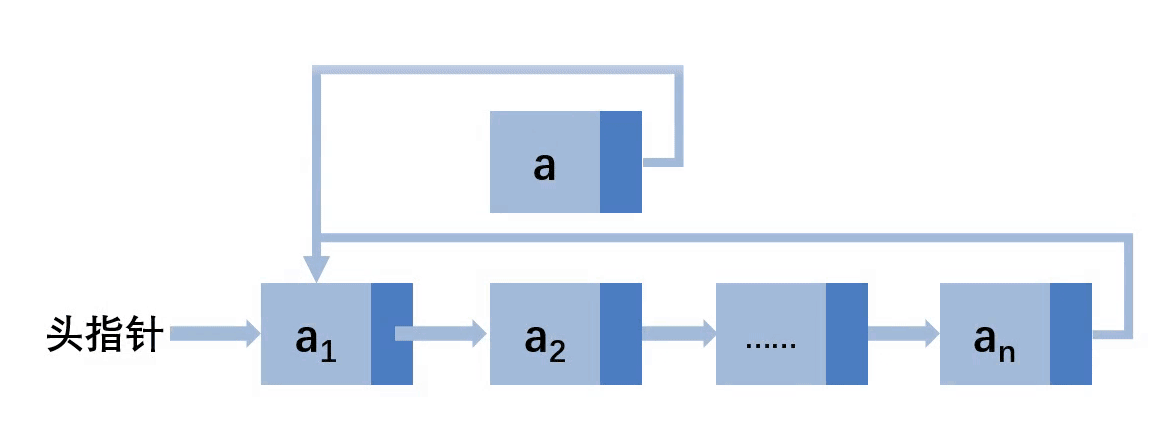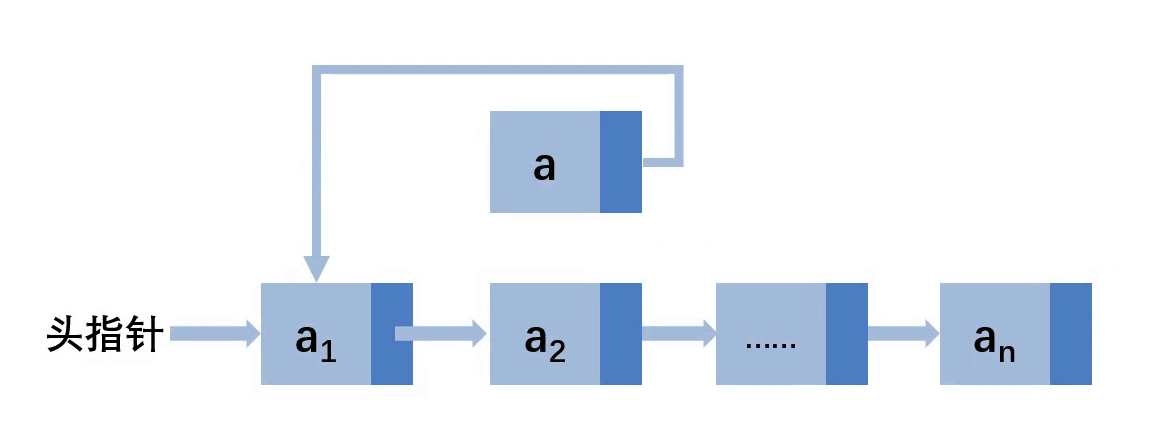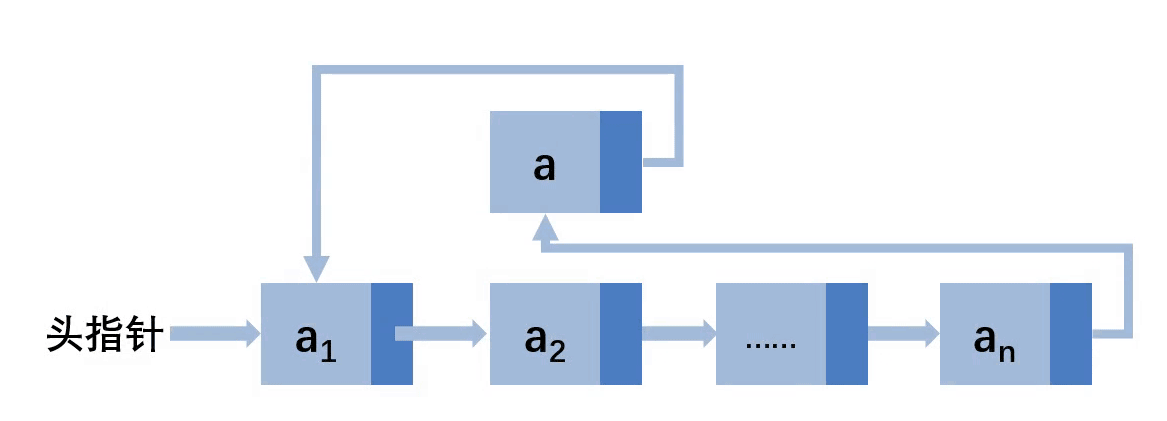
结构图
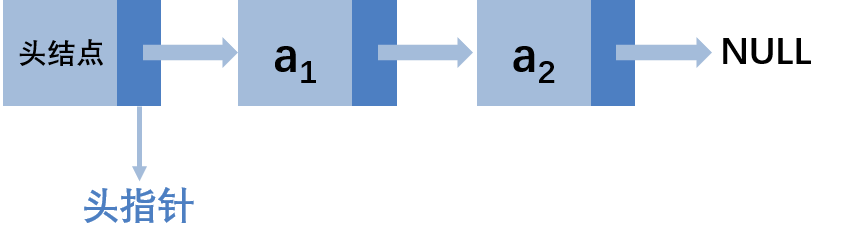
再次强调,请理解头结点和头指针,头指针不是链表的第一个结点,而是指向链表的第一个结点的地址!!
首先定义链表的结点
// 定义链表的结点
typedef struct node{
int id; //数据域,这里为了方便示例全部采用id值
struct node * next; //指针域,指向下一个结点的地址
}Node;然后定义链表的头结点与头指针
// 头结点
// 在定义链表时,习惯性的会定义头结点,以便统一链表结点的插入和删除操作
typedef struct LinkList{
Node * next; //头指针(如果链表有头结点,next就指向头结点,没有就指向第一个结点)
int length;
}LinkList;上面这段代码,你可能会好奇怎么使用,或者说为什么要这样定义,而不是只要有链表的结点不就完了吗,还要这段代码干嘛,别急后面会用到。
单链表插入
插入分为两种情况,第一种插入到第一个位置,第二种插入到其他位置。
第一种情况:插入第一个位置

从图片不难看出,首先将要插入的a结点的next指向头指针,即第一个结点(a1)的地址,然后将链表的头指针指向新插入的a结点的地址,就完成了
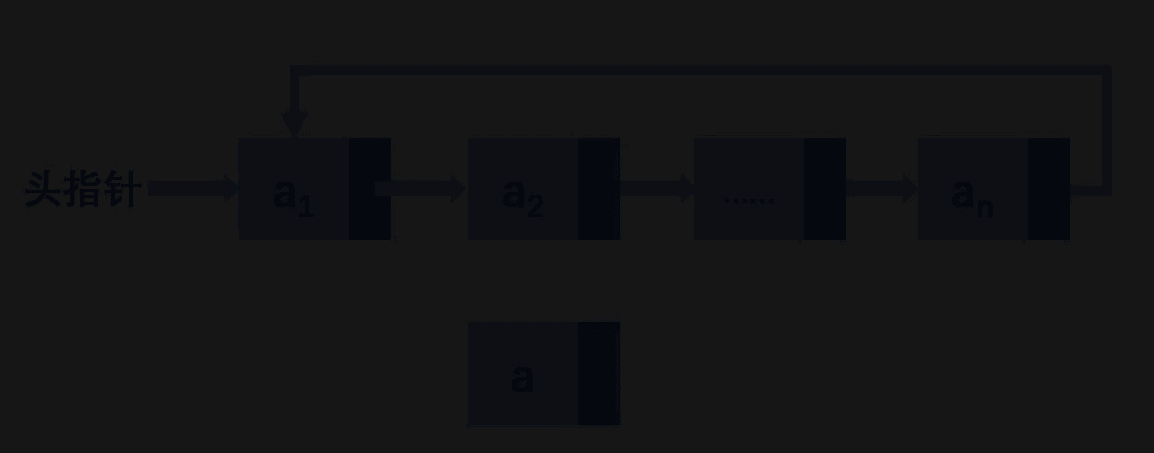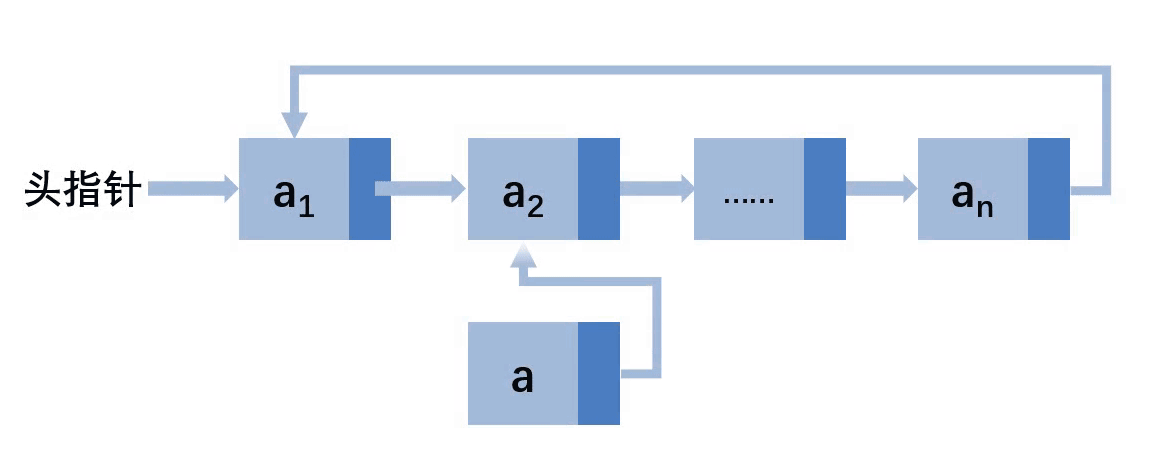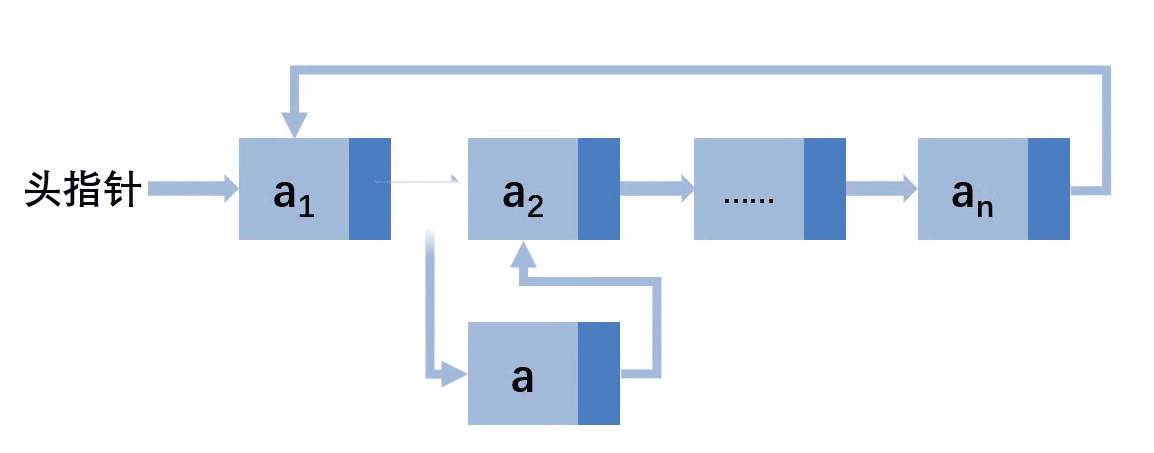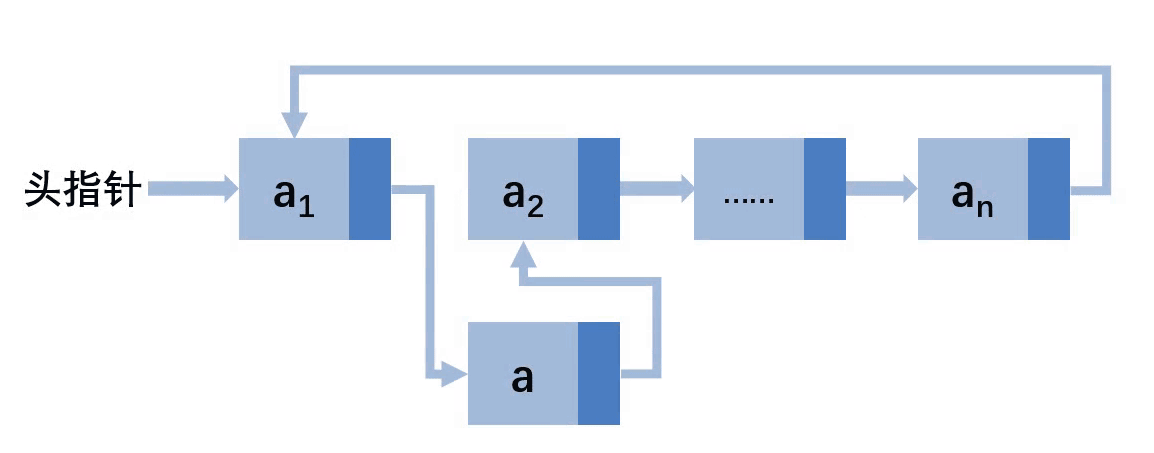
第二种情况:插入到其他位置
这里假设插入到3位置
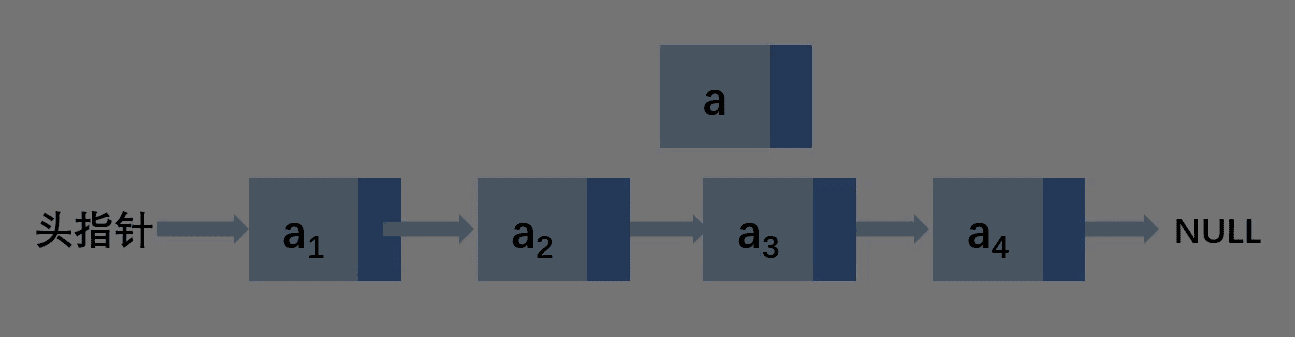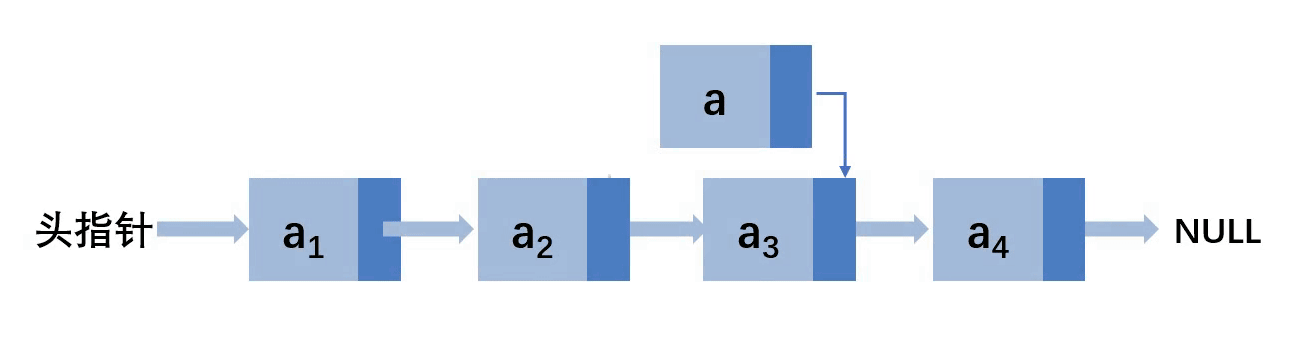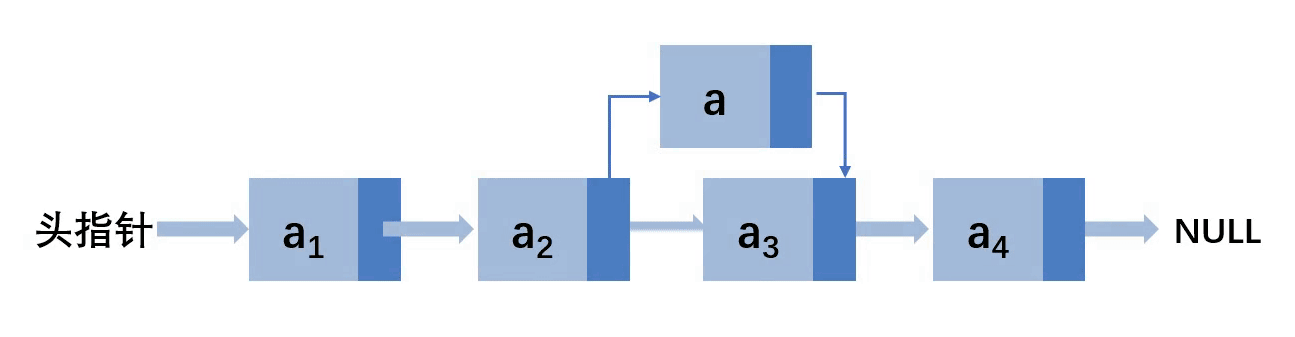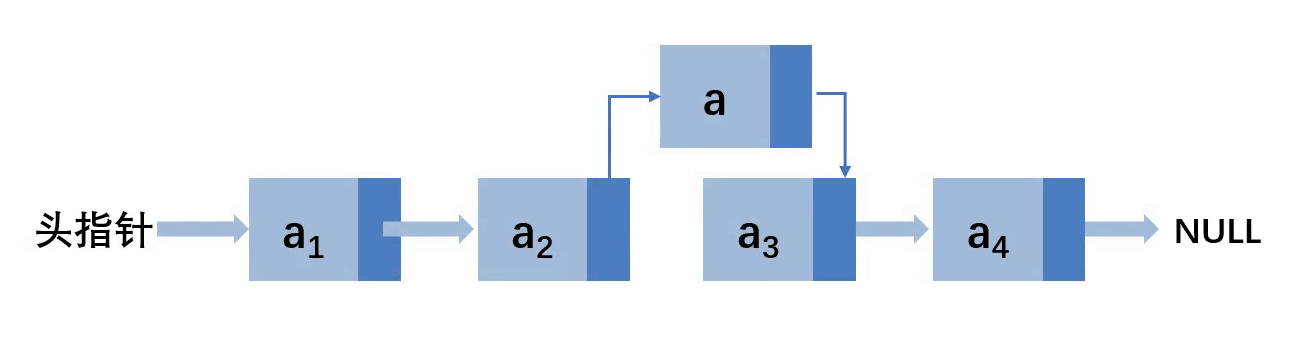
让a结点的next指向a2的next,然后a2的next指向a,就完成了插入。所以,首先要找到要插入的位置的上一个结点
// 在指定的位置pos插入元素id
void InsertLinkList(LinkList *linkList, int pos, int id)
{
// 1.创建空结点并为数据域赋值
Node *node = (Node *)malloc(sizeof(Node)); //创建结点
node->id = id;
node->next = NULL;
// 2.找到要插入位置的结点
// 如果插入的是第一个元素
if (pos == 1)
{
node->next = linkList->next;
linkList->next = node; //重新设置头指针
}
else
{
// 通过循环找到要插入的结点位置
Node *prev = linkList->next; // 获取到插入pos前一个结点的地址
for (int i = 1; i < pos - 1 && prev != NULL; i++)
{
prev = prev->next;
}
// 3.将结点插入并对接前面的结点
if (prev != NULL)
{
//必须先让插入的结点的next获取到前一个结点的next指向的地址空间,
//低下这两行代码不能调换顺序
node->next = prev->next;
prev->next = node;
}
// 并不需要单独考虑结点在最后添加的情况
// 如果在尾部添加结点。因为在前面,就设置了node->next = NULL
// 所以链表的尾结点插入好后下一个空间的地址就是空
}
linkList->length++;
}单链表初始化
定义初始化函数,此初始化只出现本篇一次,后面的双链表和循环链表将不会出现初始化示例
// 初始化链表
void InitLinkList(LinkList * linkList,int length)
{
linkList.length = 0; //初始化链表长度
//注意头指针的定义是,即使链表为空,头指针也不为空,这里是本人的代码习惯,所以将头指针设置为空
linkList.next = NULL; //初始头指针为空
for (int i = 0; i < length; i++)
{
InsertLinkList(linkList,i + 1,i + 1);
}
}单链表删除
这里也要分两种情况,第一种情况:删除的位置在第一个,第二种情况:在其他位置删除
第一种情况:删除的位置在第一个示例
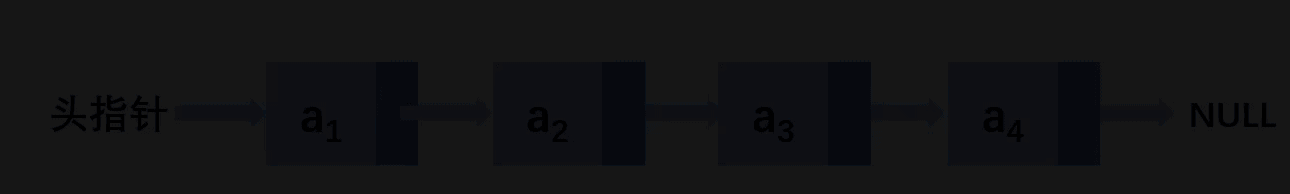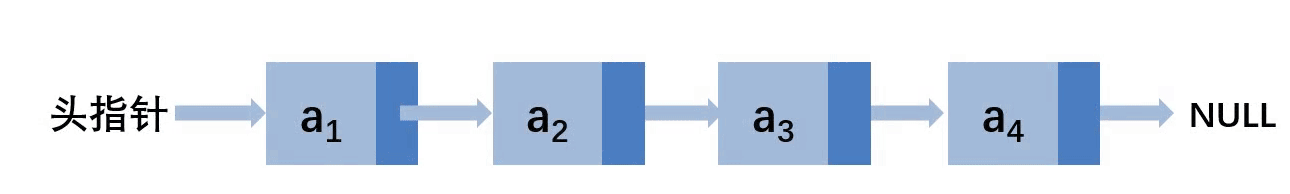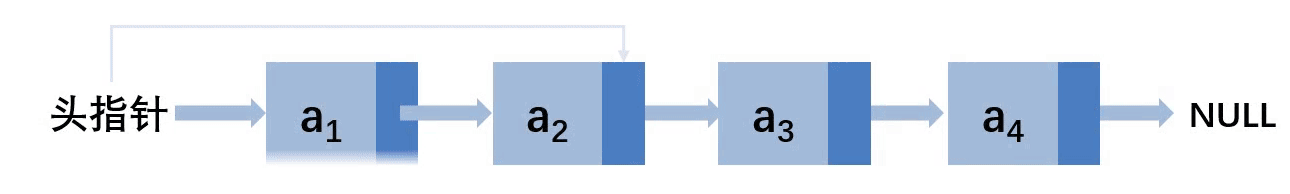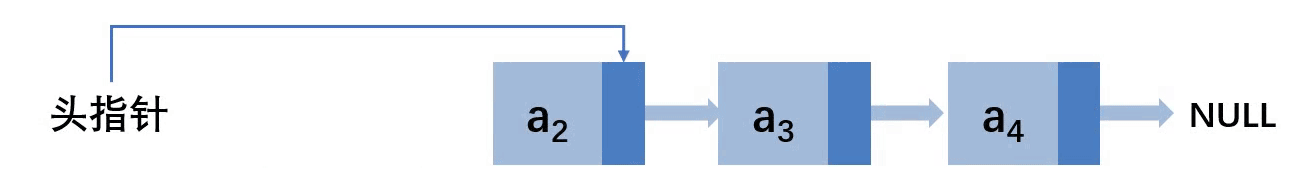
整个的逻辑其实是,直接让头指针指向a2即可,然后释放掉a1的内存空间即可
第二种情况:在其他位置删除
假设删除的位置是2,那么需要找到上一个结点,从图片可知让a1的next指向a2的next,然后释放掉a2的空间即可

// 在指定位置删除结点
void DeleteLinkList(LinkList *linkList, int pos)
{
// 1.指向链表的第一个结点
Node *node = linkList->next;
// 2.删除的结点为第一个
if (pos == 1)
{
linkList->next = node->next; //重新设置头指针
free(node); //记得要使用free(),这一步容易忽略
linkList->length--;
return;
}
// 3.获取要删除的结点的前一个结点地址
for (int i = 1; i < pos - 1; i++)
{
node = node->next;
}
Node *delNode = node->next; //要删除的结点的地址
node->next = delNode->next; //重新指向地址
free(delNode);
linkList->length--;
}清空链表
通过循环链表的方式,去清空链表,代码胜千言
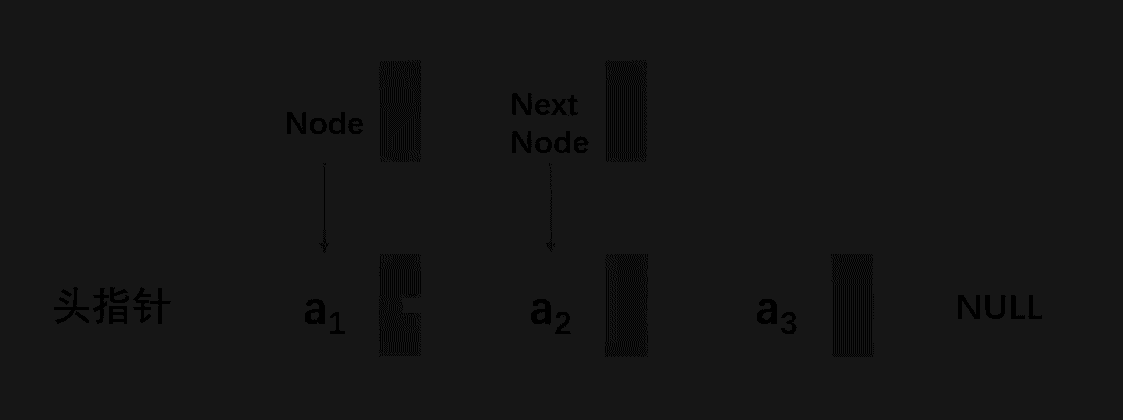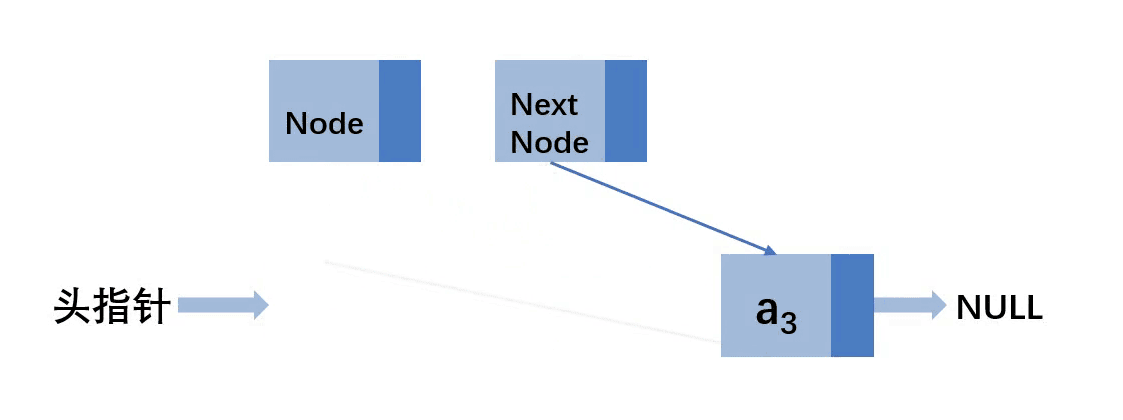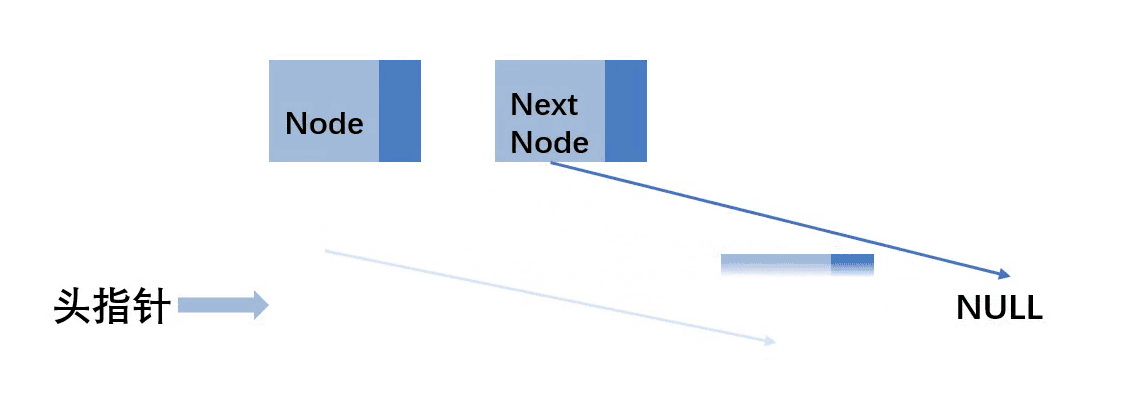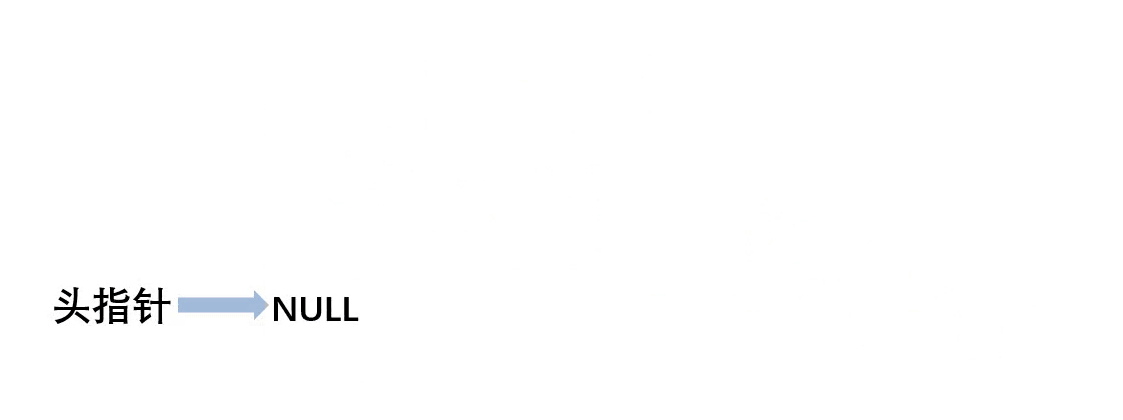
// 清空链表
void ClearLinkList(LinkList *linkList)
{
Node *node = linkList->next; //指向链表的第一个结点
Node *nextNode;
while (node != NULL)
{
nextNode = node->next; //先记录当前结点的下一个结点以便释放当前结点的内容
free(node);
node = nextNode; //重新获取结点
}
linkList->next = NULL;
linkList->length = 0;
}打印链表
void PrintLinkList(LinkList *linkList)
{
Node *node = linkList->next; //获取到链表的第一个结点
if (node == NULL)
{
printf("链表为空\n");
return;
}
while (node != NULL)
{
printf("%d ", node->id);
node = node->next;
}
printf("\n");
}main函数展示,本篇也只出现这一次,其他类型的链表main内容都大同小异
int main()
{
LinkList linkList;
InitLinkList(&linkList, 4);
PrintLinkList(&linkList);
InsertLinkList(&linkList,1,2);
DeleteLinkList(&linkList,1);
ClearLinkList(&linkList);
PrintLinkList(&linkList);
}理解了单链表后,那么后面的循环链表和双向链表都大同小异。而从上面的代码中可看出头指针是非常重要的,用起来非常方便。
循环链表
结构图

循环链表最大的特点是尾结点的指针域指向第一个结点
定义循环链表的结点
// 循环链表的结点
typedef struct CircularNode
{
int id; //数据域
struct CircularNode *next; //指向下个结点的指针域
} CircularNode;定义循环链表的头结点
// 头结点
typedef struct CircularLinkList
{
CircularNode *next; //指向第一个结点的指针,头指针
int length;
} CircularLinkList;循环链表的插入
循环链表的插入稍微复杂了一点点,有4种情况
第一种:插入位置在第一个,链表长度不为0
第二种:插入位置在第一个,链表长度为0
第三种:插入位置在尾部
第四种:插入位置在非上述情况
虽然看起来要四种情况,但其实总的来说只有两大种,其他两小种只需要在里面,加一个if判断就能搞定
第一种:插入位置在第一个,链表长度不为0

先让a结点的next指向第一个结点的地址,然后让尾结点的next指向a结点的地址,最后头指针指向a结点的地址即可
第二种:插入位置在第一个,链表长度为0

直接让头指针指向即可
第三种:插入位置在尾部
第四种:插入位置在非上述情况
可以看到在非第一个位置插入的情况下,都需要找到前缀结点,先让a结点的next指向前缀结点的next,在让前缀结点的next指向a。如果插入的位置在最后需要更新尾结点指针域
// 在循环链表指定位置插入元素
void InsertCircularLinkList(CircularLinkList *linkList, int pos, int id)
{
// 创建一个空节点
CircularNode *node = (CircularNode *)malloc(sizeof(CircularNode));
node->id = id;
node->next = NULL;
// 插入的位置是第一个
if (pos == 1)
{
node->next = linkList->next;
// 如果长度不为0,就要找到链表的最后一个结点
if (linkList->length != 0)
{
CircularNode *lastNode = linkList->next;
for (int i = 1; i < linkList->length; i++)
{
lastNode = lastNode->next;
}
// 重新设置尾结点
lastNode->next = node;
}
linkList->next = node; //重新设置头结点
linkList->length++;
return;
}
CircularNode *currNode = linkList->next; //找到要插入的上一个结点地址
for (int i = 1; i < pos - 1 && currNode != NULL; i++)
{
currNode = currNode->next;
}
node->next = currNode->next;
currNode->next = node;
// 插入的结点在尾部
if (pos == linkList->length)
{
node->next = linkList->next; //设置尾结点指针域
}
linkList->length++;
}循环链表的删除
删除分为两种情况
第一种:在第一个位置删除
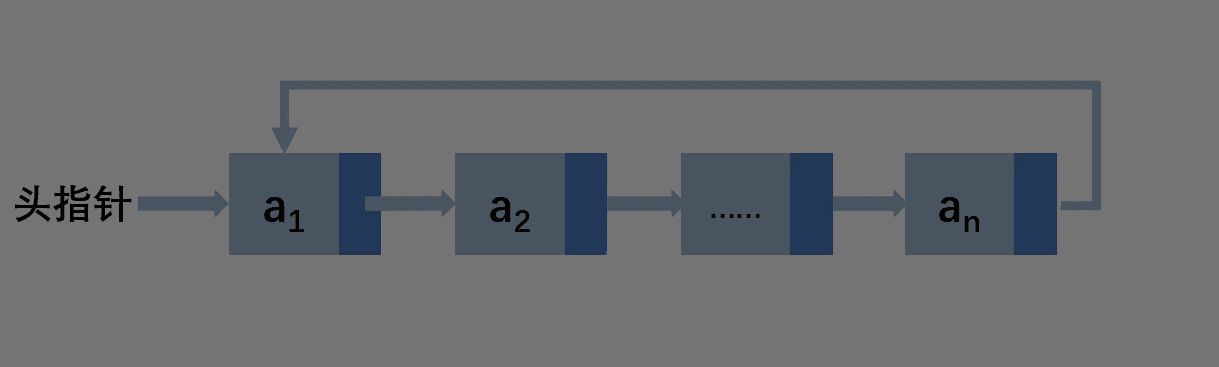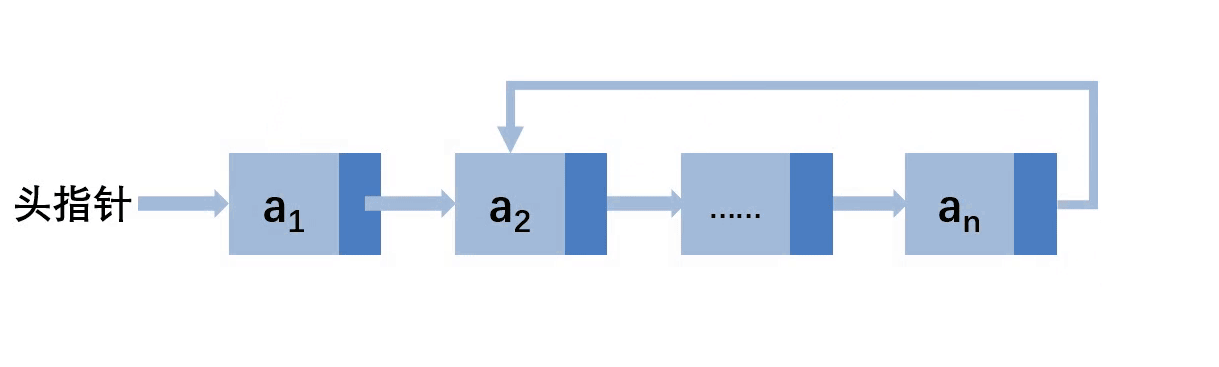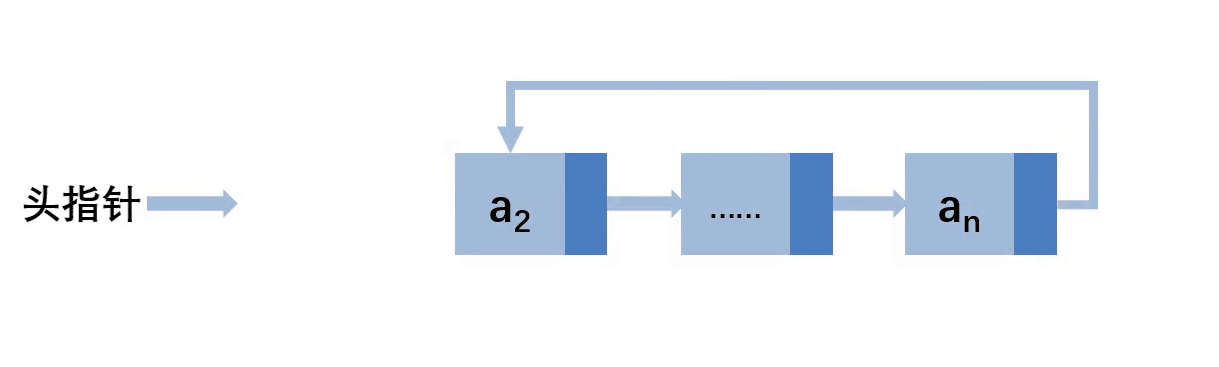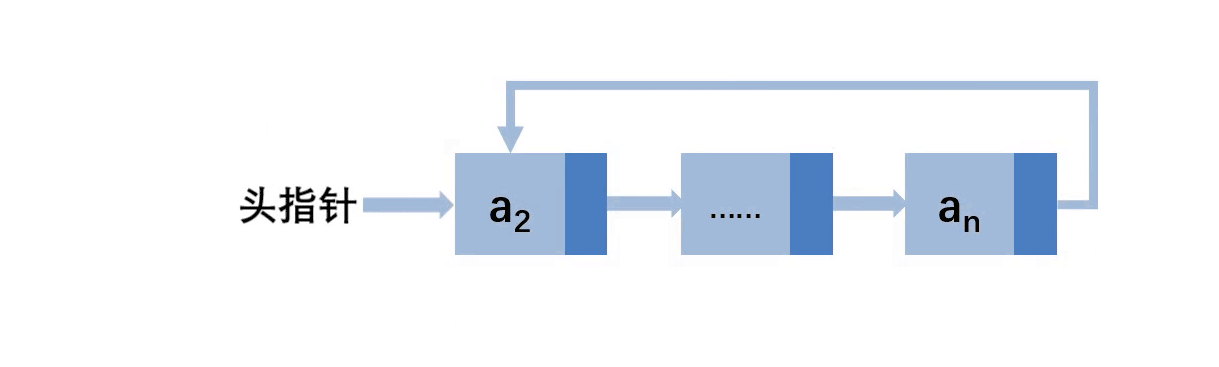
先让尾结点的next指向a2,此gif下的一步应该是让头指针指向a2,为了方便演示故此顺序不一样,最后free(a1)即可
第二种:在其他位置删除
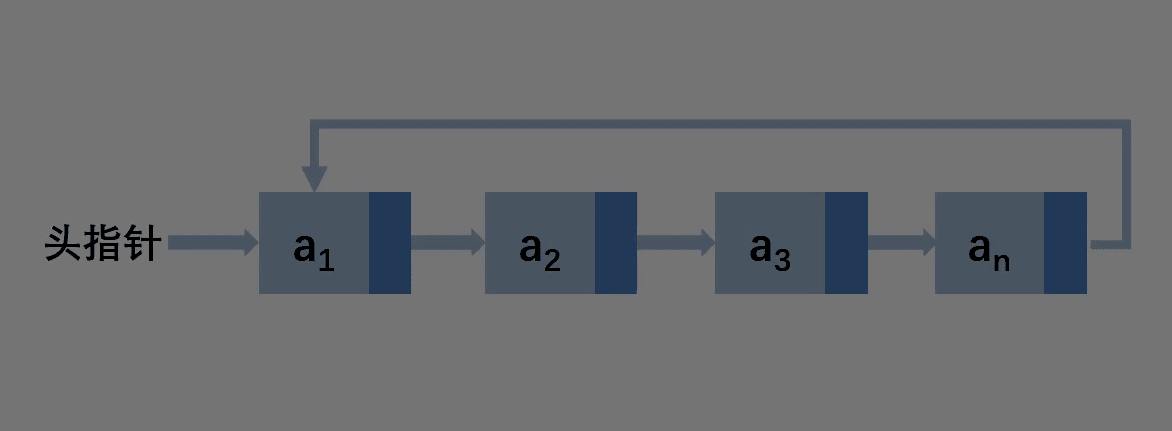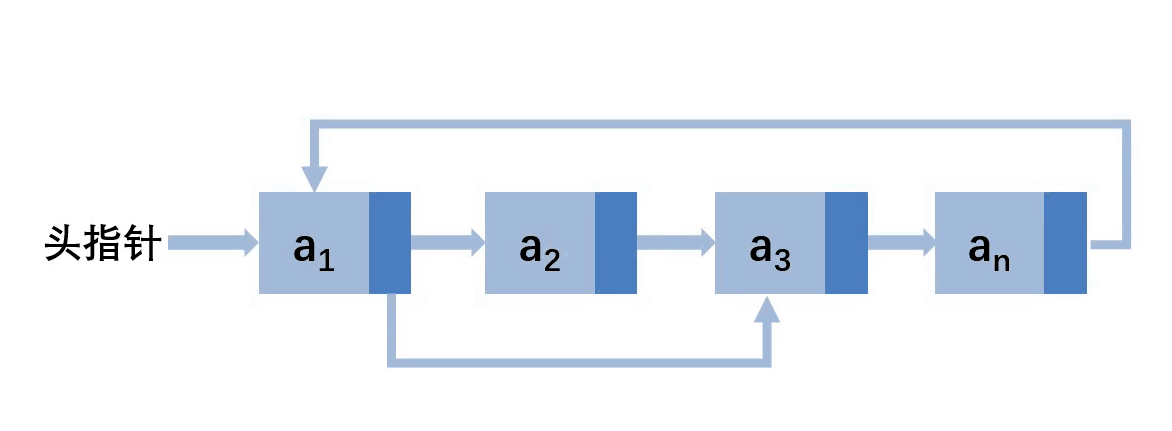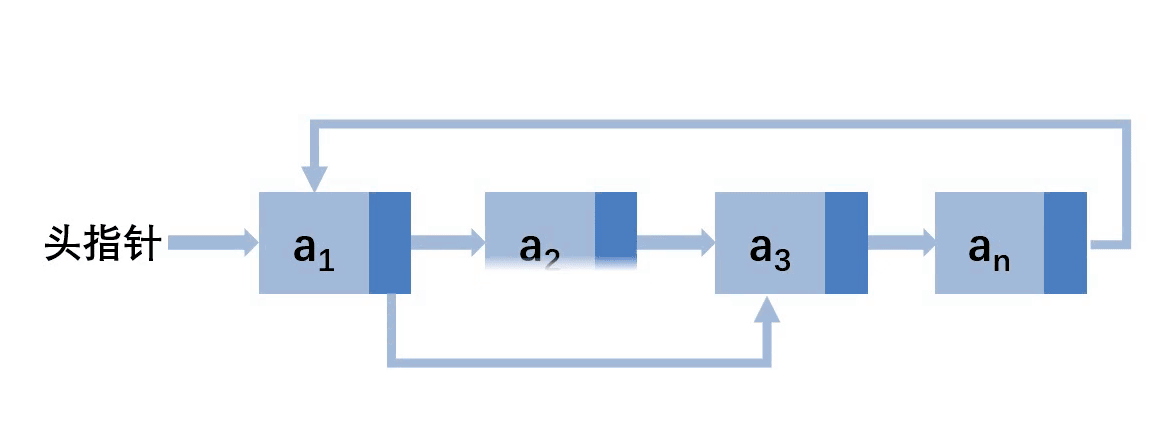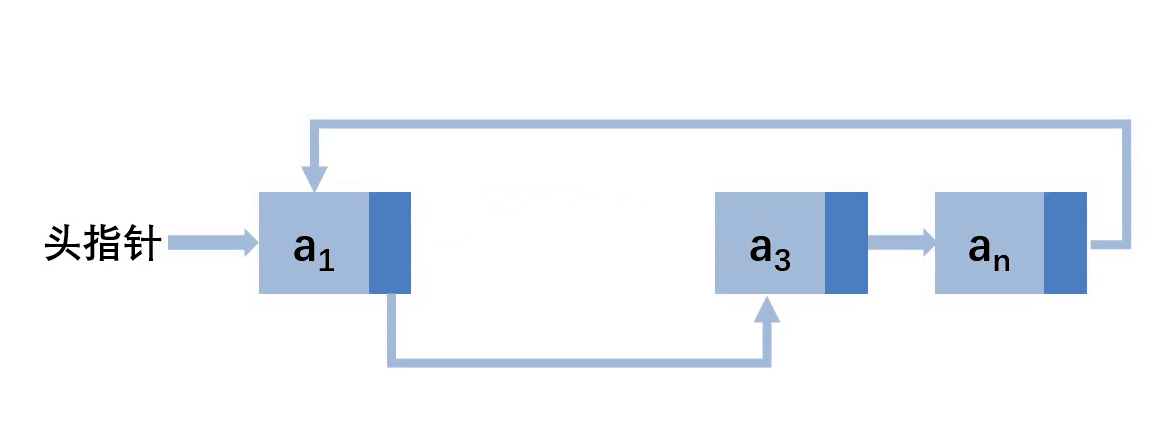
其实循环链表的删除和单链表的删除基本是一模一样的,无非就是多了一个更新尾结点的操作
// 删除循环链表中指定位置的元素
void DeleteCircularLinkList(CircularLinkList *linkList, int pos)
{
CircularNode *node = linkList->next;
if (pos == 1)
{
CircularNode *lastNode = linkList->next; //找到最后一个结点
for (int i = 1; i < linkList->length; i++)
{
lastNode = lastNode->next;
}
lastNode->next = node->next; // 重新设置尾指针
linkList->next = node->next; // 重新设置头指针
}
else
{
// 找到要删除的结点的前一个结点
CircularNode * preNode = linkList->next;
for (int i = 1; i < pos - 1; i++)
{
preNode = preNode->next;
}
node = preNode->next; //要删除的结点地址
preNode->next = node->next;
}
free(node);
linkList->length--;
}循环链表的特殊遍历法
通过给定的某个位置,循环遍历出链表中的每个元素
只需要先拷贝当前要位置的结点的地址,用do while循环遍历,当下一个地址不等于拷贝的地址就循环打印即可
// 通过给定的某个位置,循环遍历出链表中的每个元素
void PrintCircularLinkListByNode(CircularLinkList * linkList,int pos)
{
CircularNode * node = linkList->next;
if(node == NULL || pos <= 0 || pos > linkList->length)
{
return NULL;
}
//获取到pos位置的结点的地址
for (int i = 1; i < pos; i++)
{
node = node->next;
}
CircularNode * BackupNode = node; //拷贝该结点的地址
do
{
printf("%d ",node->id);
node = node->next;
}while(node != BackupNode);
}双向链表
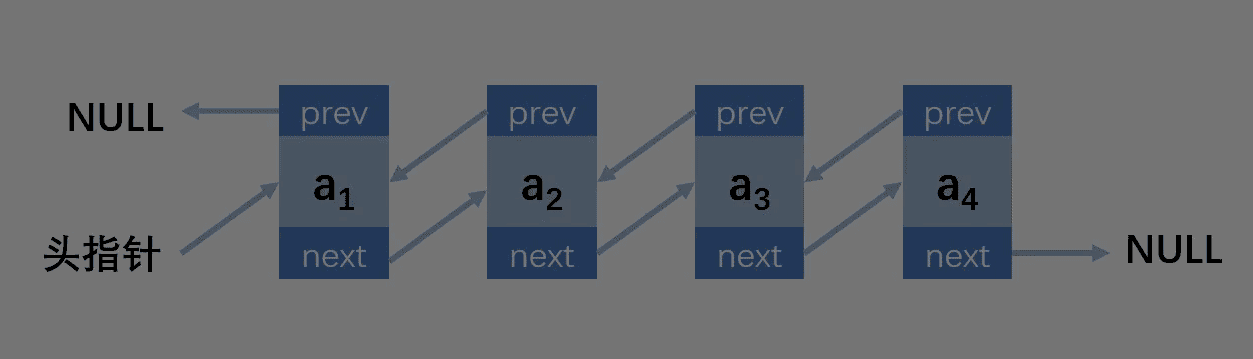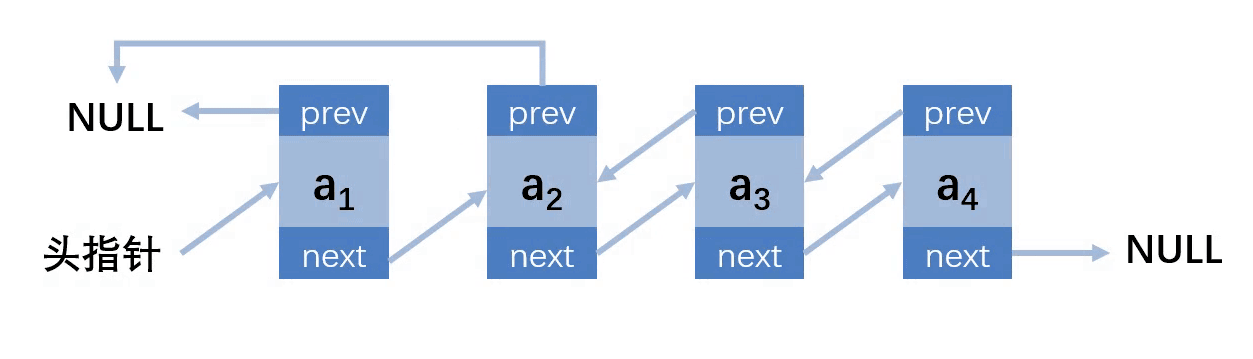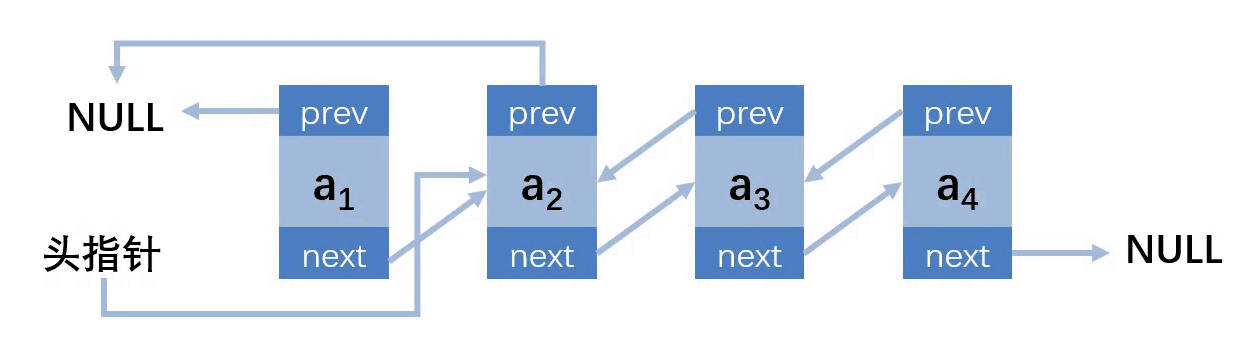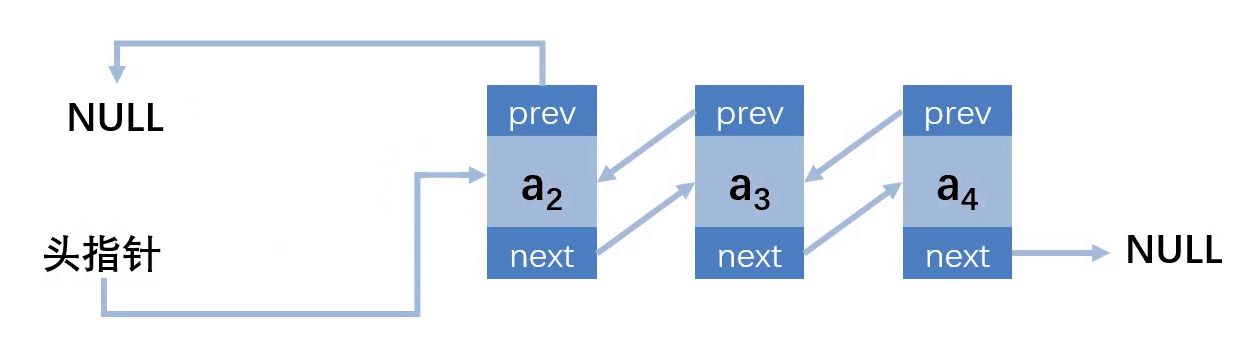
双向链表只是在单链表的基础上,多了一个前缀结点,就多了一份存储空间,相当于用空间换时间
结构图

老规矩,先创建结点和头结点
/** 双向链表的结点,包含一个数据域和两个指针域 */
typedef struct Node{
int id;
struct Node * next; //指向前缀结点
struct Node * prev; //指向后继结点
}Node;/** 双向链表 */
typedef struct LinkList{
int length;
Node * next;
}LinkList;双向链表的插入
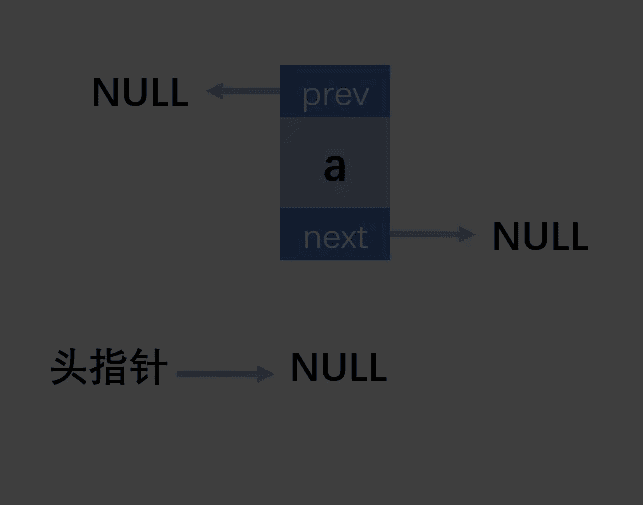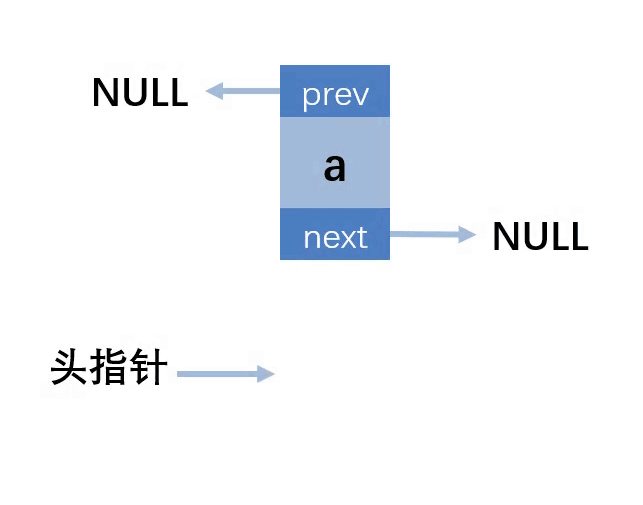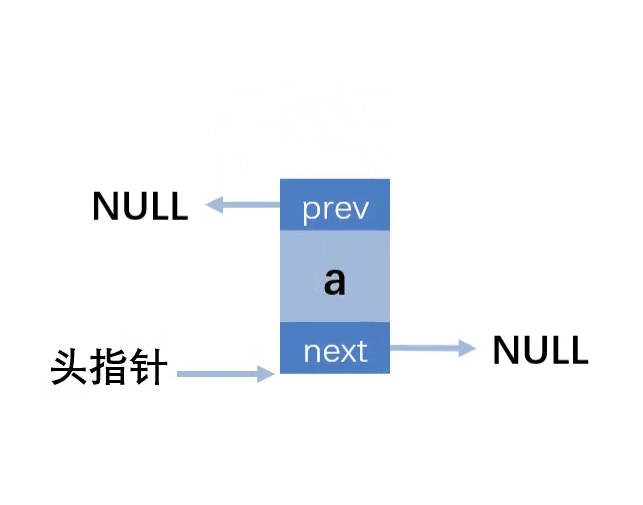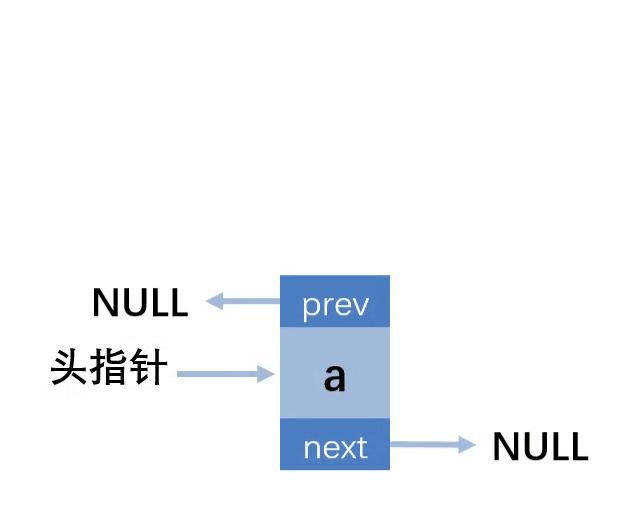
第一种情况:插入的位置在第一个,链表为空
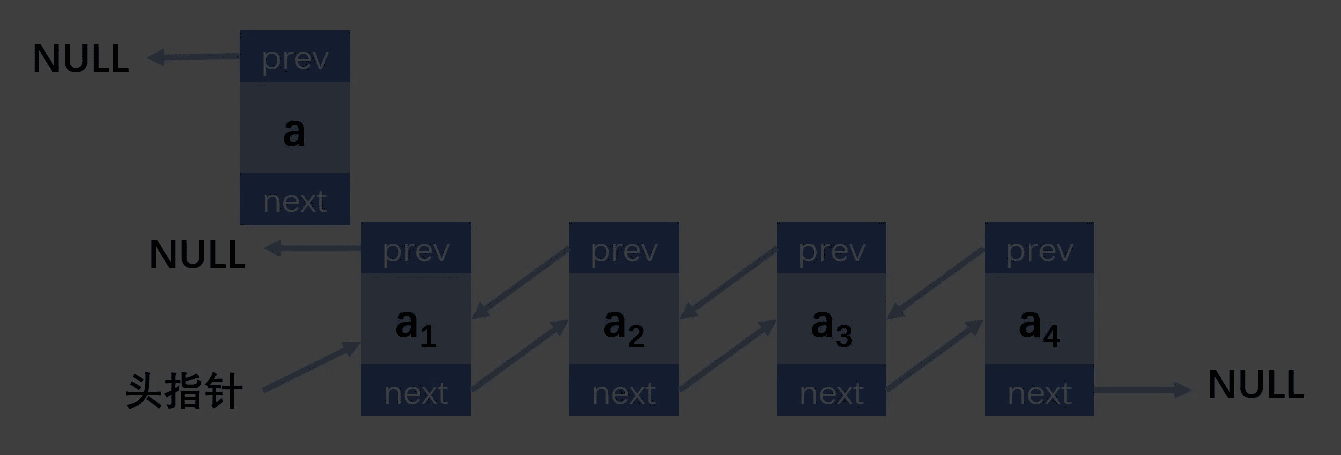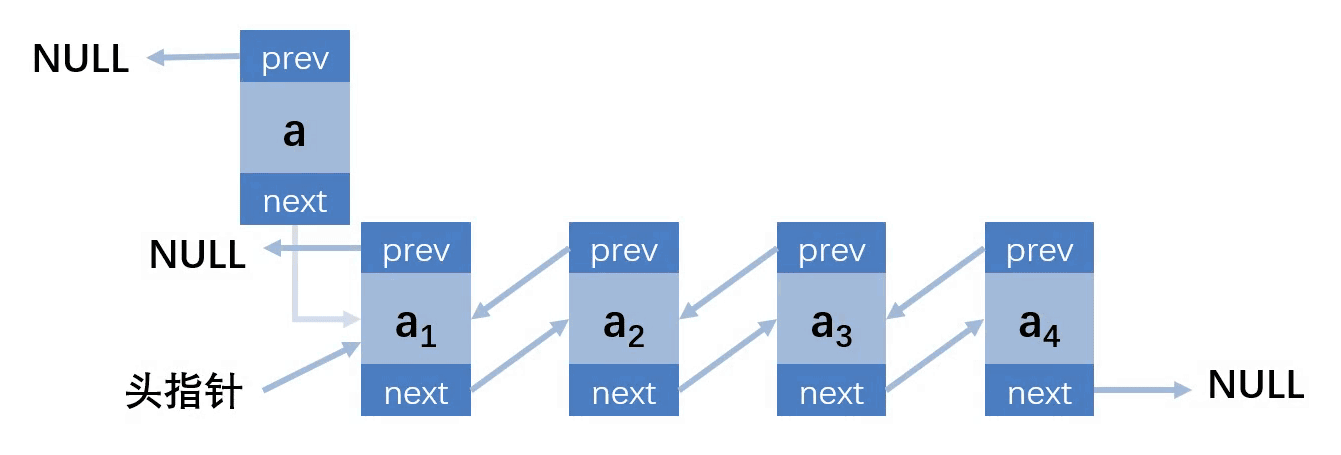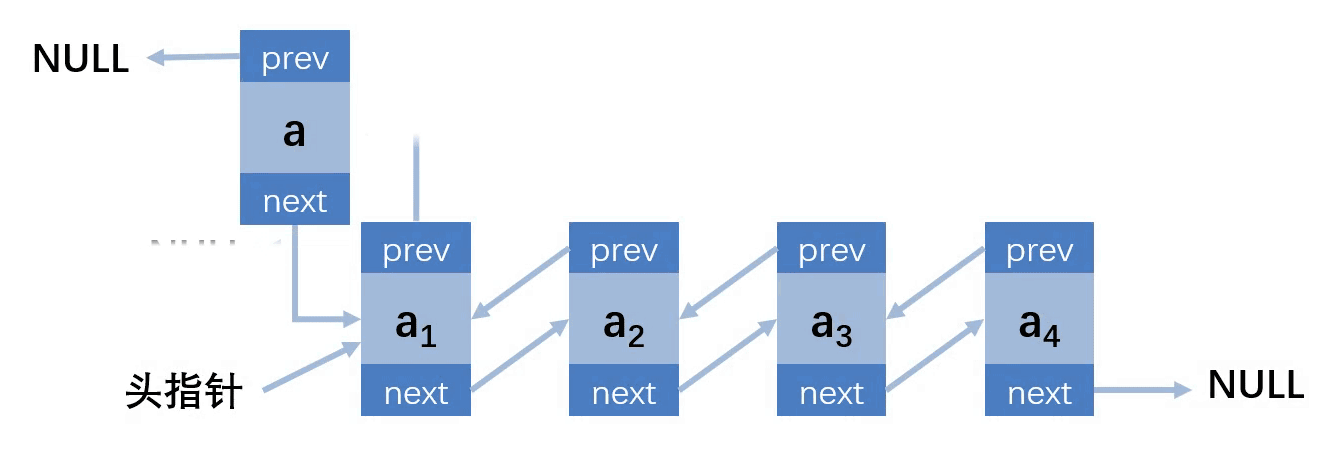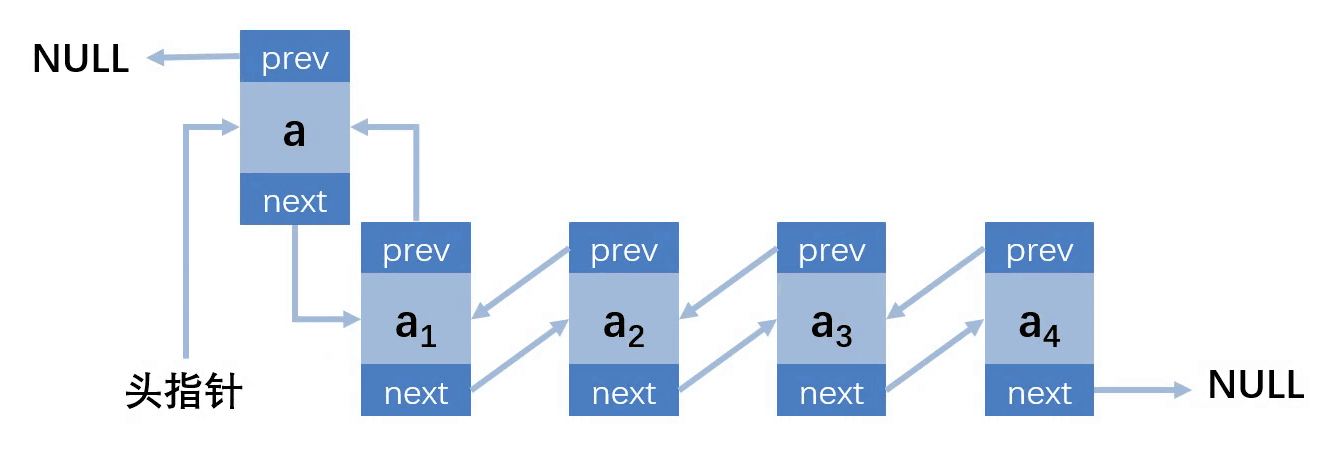
第二种情况:插入的位置在第一个,链表不为空
第三种情况:插入的位置在中间
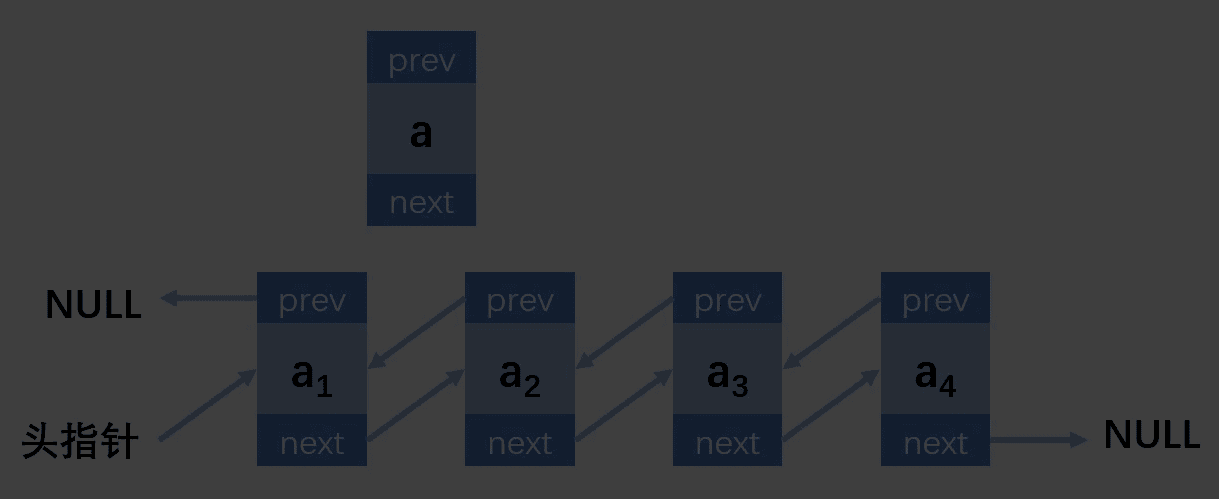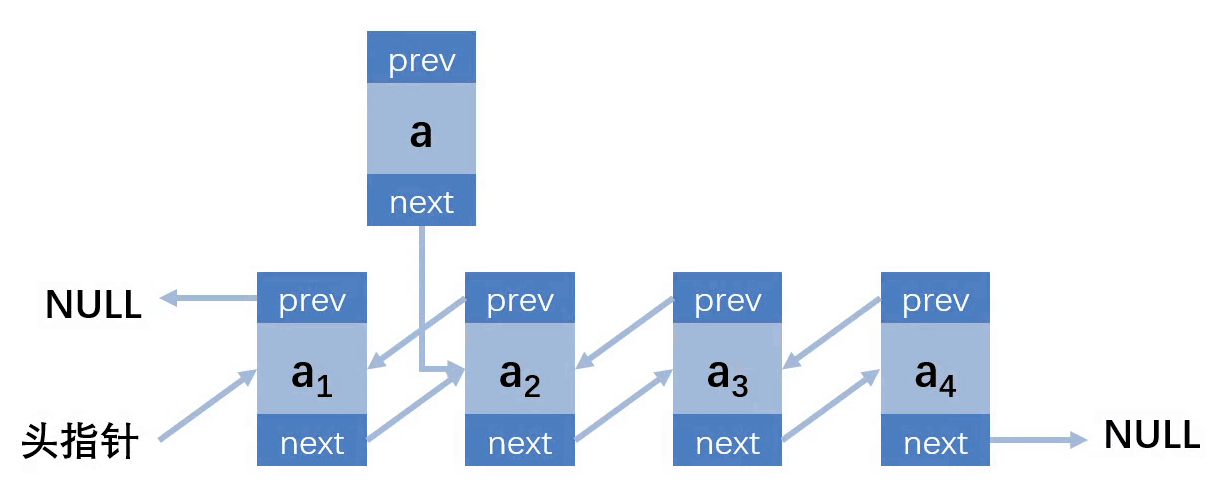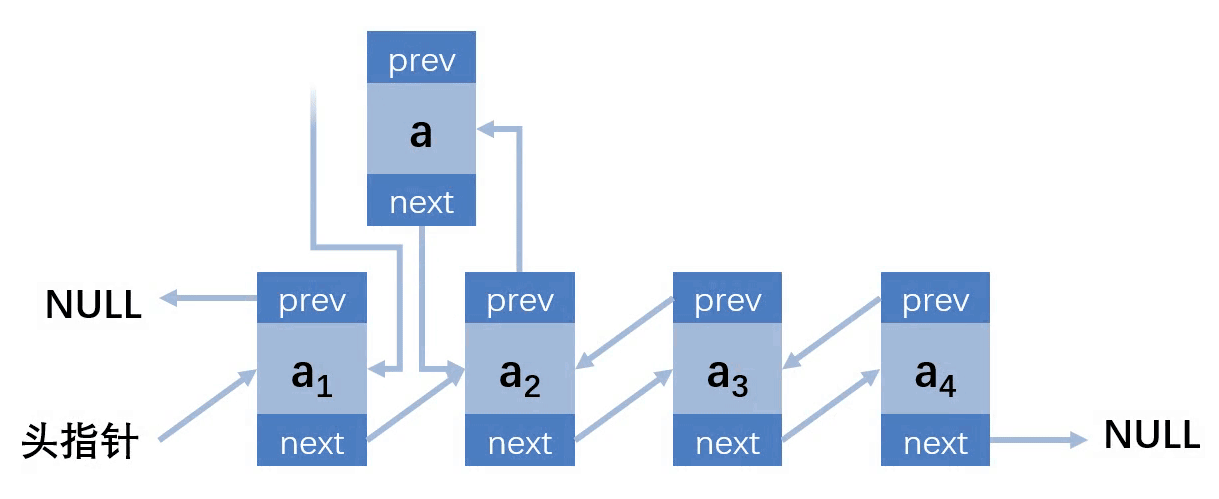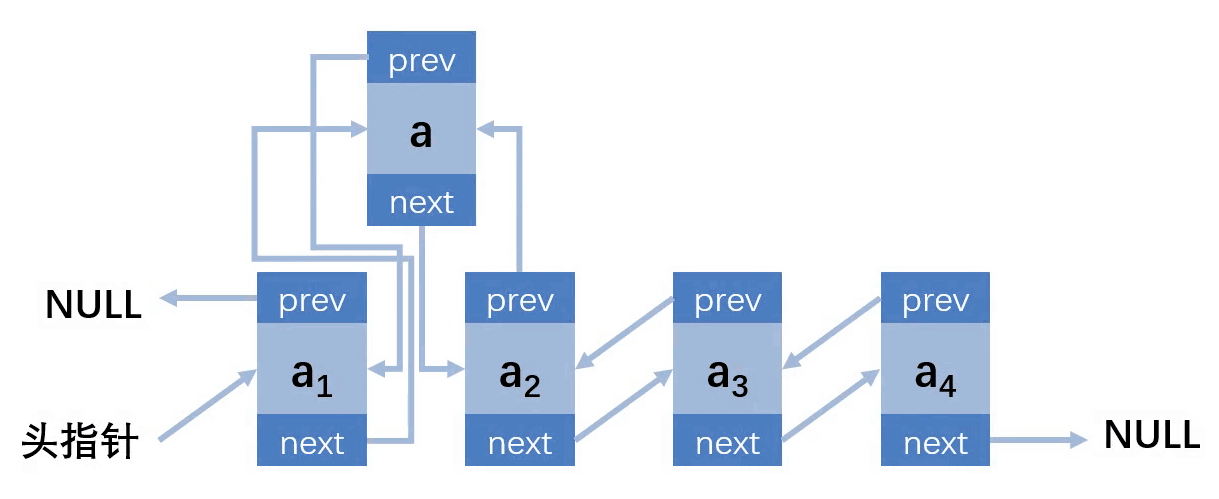
第四种情况:插入的位置在最后
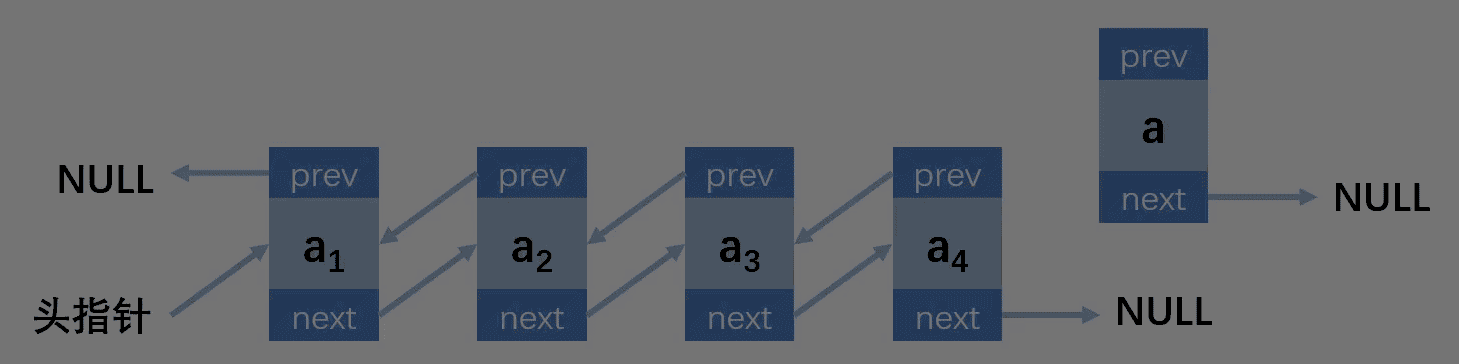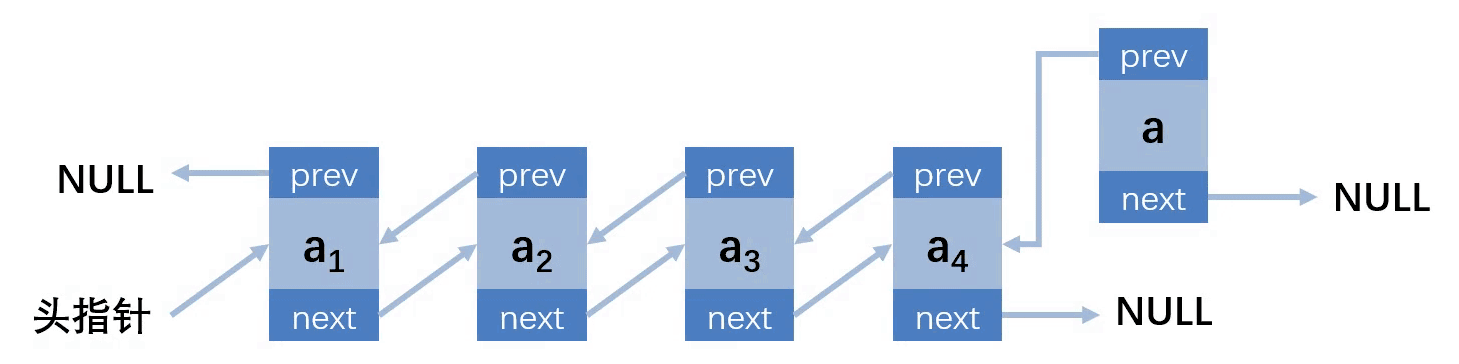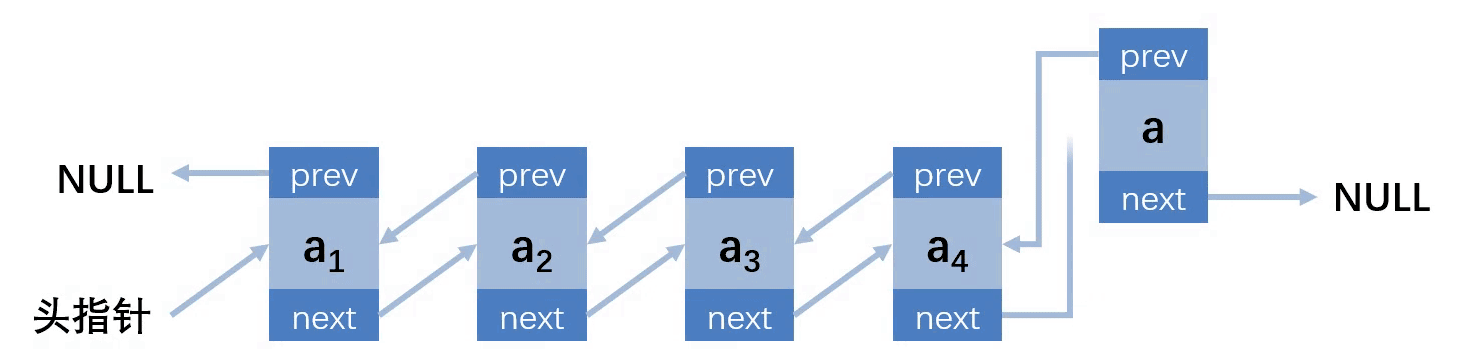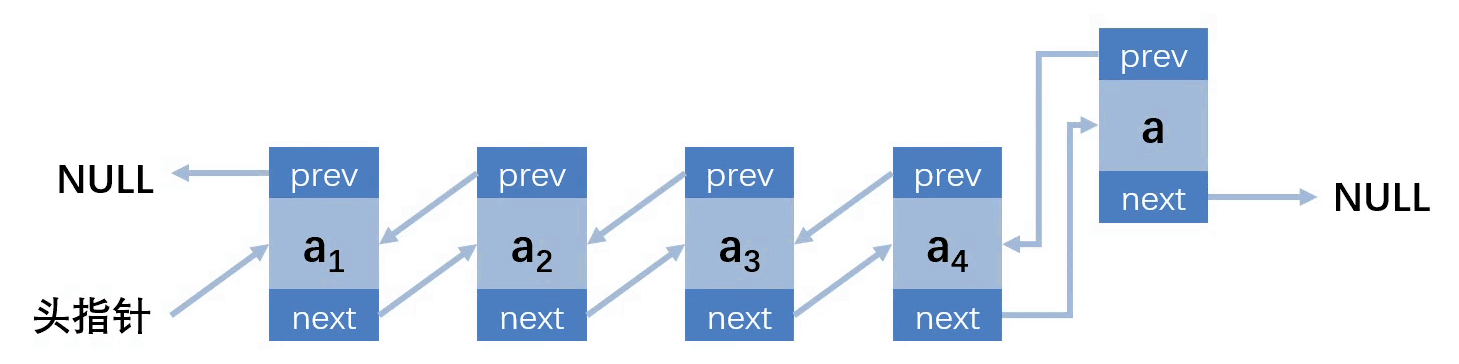
// 向双向链表指向位置插入元素
void InsertDoublyLinkList(LinkList * linkList,int pos,int id)
{
// 创建空结点
Node * node = (Node *)malloc(sizeof(Node));
node->id = id;
node->next = NULL;
node->prev = NULL;
if(pos == 1)
{
//链表不为空
if(linkList->length != 0)
{
node->next = linkList->next;
linkList->next->prev = node;
}
linkList->next = node; //更新头指针
}
else
{
Node * preNode = linkList->next; //获取到要插入位置的前缀结点
for (int i = 1; i < pos - 1; i++)
{
preNode = preNode->next;
}
// 在中间插入
if (preNode->next != NULL)
{
node->next = preNode->next;
preNode->next->prev = node;
}
node->prev = preNode;
preNode->next = node;
}
linkList->length++;
}双向链表的删除
第一种情况:删除的位置在第一个,链表长度为1
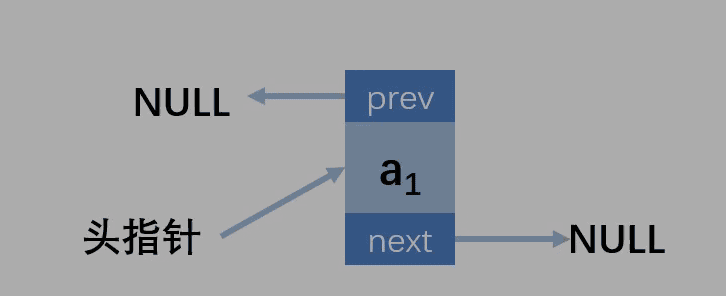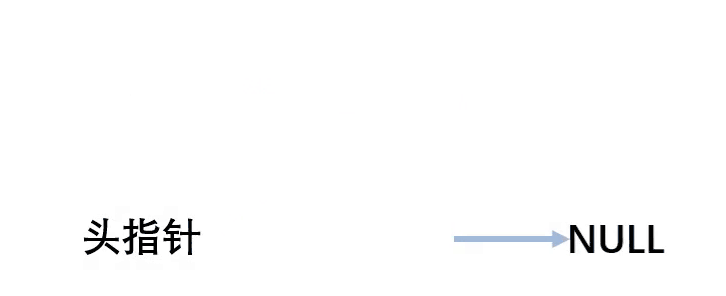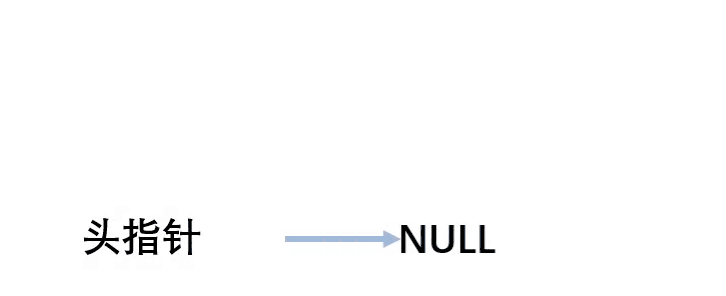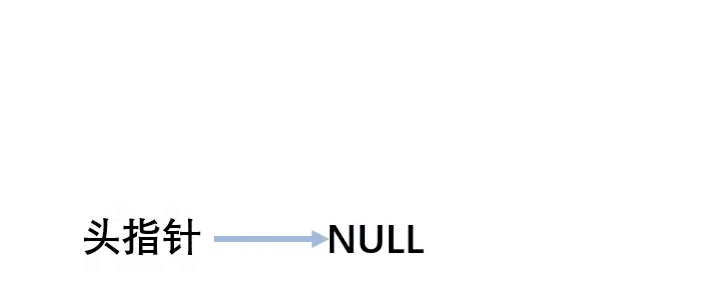
请勿将代码直接写成 头指针=null (linkList->next = null)的形式,而是换一种等价写为法:linkList->next = node->next,这种写法将直接减少代码行数
第二种情况:删除的位置在第一个,链表长度不为1
第三种情况:删除的位置在中间
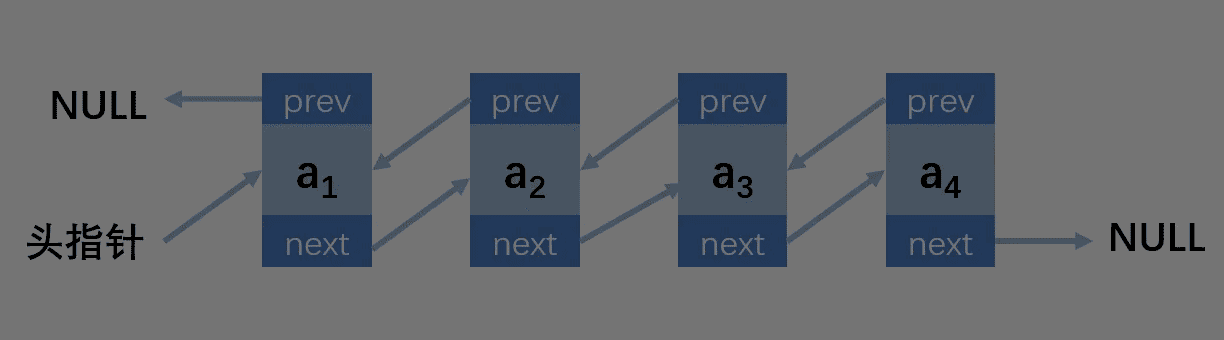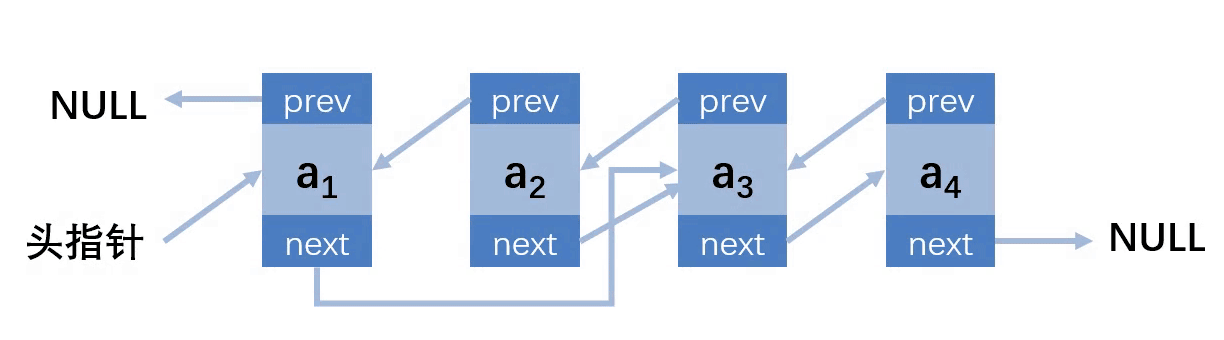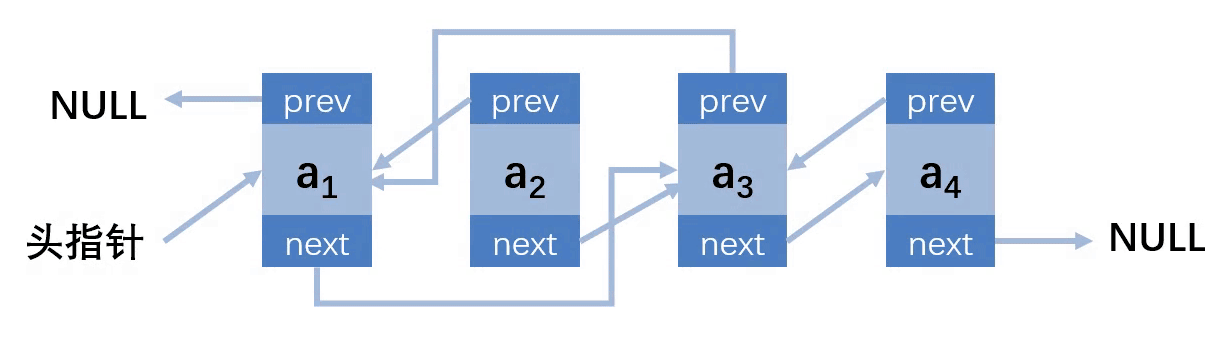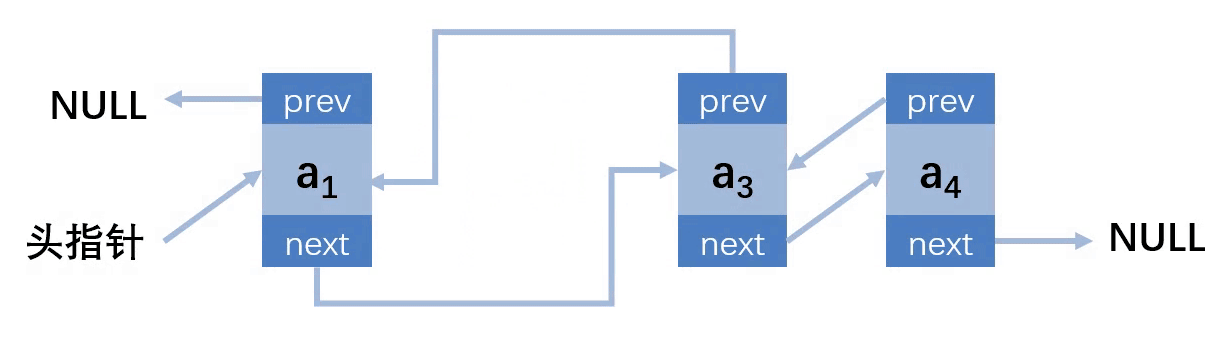
第四种情况:删除的位置在最后
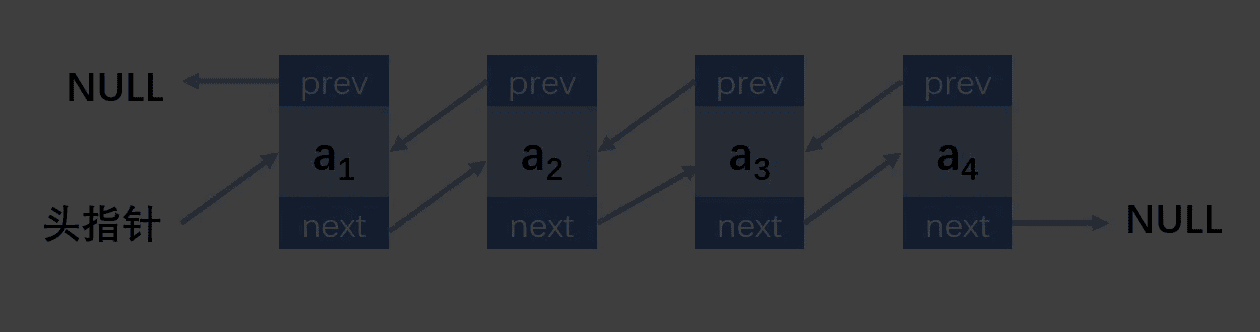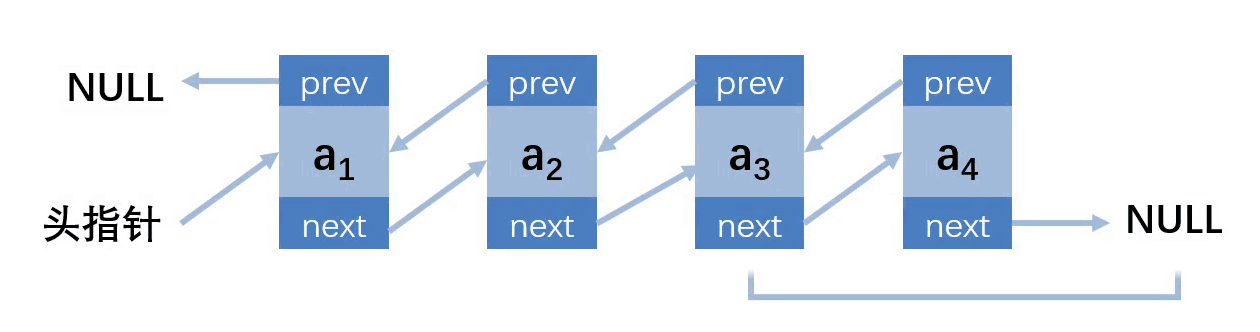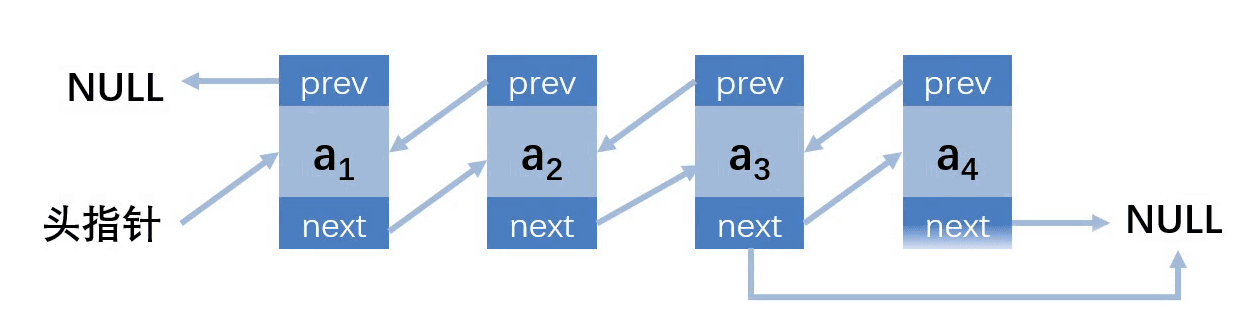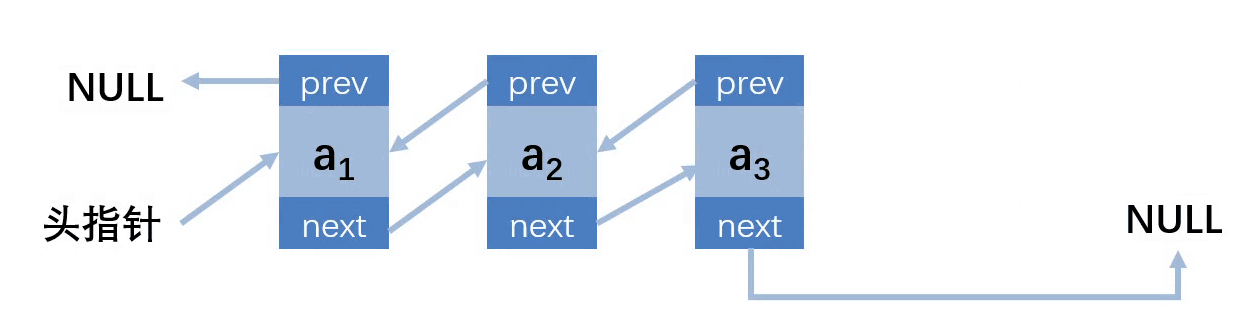
这里找删除结点跟前两个不一样,因为有了前缀结点,所以找结点的时候直接找到要删除的结点即可,而不是要删除的结点的前缀结点
// 在指定位置删除元素
void DeleteLinkList(LinkList * linkList,int pos)
{
Node * node = linkList->next; //获取到链表的第一个结点
if (pos == 1)
{
// 链表长度不为1
if (node->next != NULL)
{
node->next->prev = NULL;
}
linkList->next = node->next; //更新头指针
}
else
{
// 循环找到要删除的结点的位置
for (int i = 1; i < pos; i++)
{
node = node->next;
}
node->prev->next = node->next;
// 不是在最后一个位置删除
if(node->next != NULL)
{
node->next->prev = node->prev;
}
}
free(node);
linkList->length--;
}后记
至此,链表的核心操作就介绍完了,感谢大家的阅读!为了更好的理解链表的详细操作步骤,本人花费大量的时间做出这些gif图片。如果你要使用这些图片,请包含出处等信息,在此谢谢各位大佬!